The translation and localization industry has its own terminology and jargon, which might not be immediately obvious to everyone else. I’ve been working in the translation and localization industry since 2007, mostly as a video game translator (English/German), so let me take you by the hand and explain some of the common terms in video game translation (and translation in general) to you.
Source Language, Target Language
This one is easy: The source language is the language used as a basis (or source) for translation. The target language is the language you are translating into.
Translation, Localization, Internationalization
These are some very basic terms in the translation industry which still cause a lot of confusion, possibly because at least translation and localization are often used interchangeably.
What is the difference between translation and localization?
Translation is changing text from one language into another (like translating a confirmation button reading “Yes” to read “Ja” in German). Localization on the other hand also includes adjusting the text or product to fit the target culture (like changing a green confirmation button to a red one for the Japanese market).
As for internationalization: I’ve already explained this in my post Is video game localization worth it? with some examples, but essentially, internationalization is the process of designing software in a way that makes localization possible.
So internationalization is concerned with making it possible for foreign special characters (ä, ö, ü) to be displayed properly in the game, whereas localization is concerned with changing the English text to German text – ideally one that doesn’t sound like it was translated in the first place.
FIGS, EFIGS, FIGSDRP, CJK, LATAM
These combinations of letters are an abbreviation for a set of languages, usually the languages a game is localized into or published in. In particular, they are:
- FIGS: French, Italian, German, Spanish
- EFIGS: English, French, Italian, German, Spanish
- FIGSDRP: French, Italian, German, Spanish, Dutch, Russian, Portuguese
- CJK: Chinese, Japanese, Korean
- LATAM: LATAM is short for Latin America and refers to Spanish and Brazilian Portuguese
CAT tool
CAT stands for computer-assisted translation (or computer-aided translation) and refers to software translators use to facilitate translation. CAT tools are different from machine translation in that it is still the translator doing the translation, but they may use software (like memoQ, SDL Trados or OmegaT) that use translation memories, termbases and spellcheckers.
Translation Memory (TM)
A translation memory (or TM for short) is a system that stores translations as sentence segments and compares new segments with existing ones to find matches or partial matches. All this is done in order to facilitate and speed up translation, as well as ensure consistency in a project (or across several projects).
If your software uses the string “Do you want to save your changes before you proceed?” several times, a TM will flag this to you and, depending on your settings, either fill all occurrences of this sentence in once you’ve translated the first one, or it will flag the occurrence to you as a 100% match once you get to the sentence the second time. As a consequence, this sentence will always be translated the exact same way (so it will be consistent throughout the project) and the translator saves time by not having to type the sentence twice.
Some translators give discounts for repetitions and/or partial matches – the downside of this, however, is that text might look like a repetition when it isn’t. If one cell says “Close” in the context of closing a window, the next “Close” will be translated just like that, even if the context is “Close” as opposed to “Far”. This is the price developers or agencies pay for not having to pay for 100% matches and repetitions. Luckily, things like this are easily caught during testing.
100% Matches, Fuzzy Matches, Repetitions
I’ve mentioned repetitions already: Repetitions are repeated segments. Translation memory systems can just fill those in whenever they appear. Now maybe you’re wondering: What’s the difference between a repetition and a 100% match?
Repetitions are repeated segments within a text – they are independent of any connected translation memories. In contrast, 100% matches are segments that match up with segments in a translation memory. So in a brand new file without any connected TMs, the first occurrence will be a “no match” and all additional occurrences will be repetitions. If a segment is already present in a connected translation memory, it will be a 100% match instead.
Fuzzy matches are partial matches the TM will display to the translator. If one sentence is “You have died of dysentery.” and another “You have died of exposure.”, TMs will flag this as a fuzzy match and depending on the settings might already paste the fuzzy match in the translation column. The translator can then use this as a basis and only make the necessary changes to reflect “exposure” instead of “dysentery”.
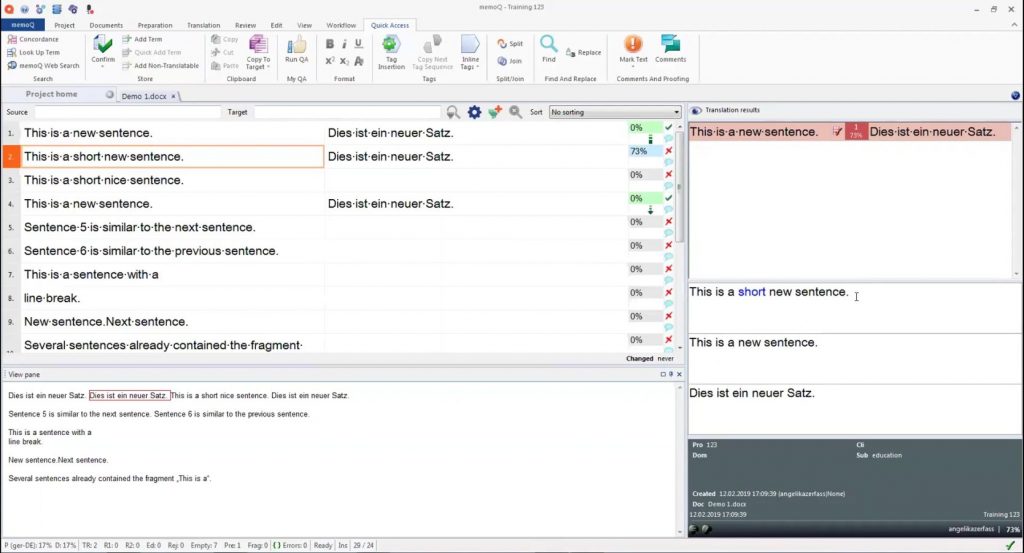
Term Base (TB)
Term bases are glossaries that will detect words in the source text and display the correct term in the target language. As any glossary does, they help maintain consistency for specific terms. If your item is called “Thor’s Hammer” at one point, you don’t want it to be called “Hammer of Thor” later.
LQA
LQA stands for Language Quality Assurance, Linguistic Quality Assurance or Localization Quality Assurance. It is a process to ensure the quality of a localized product.
In video games, LQA usually involves playing the finished product and flagging typos and grammar mistakes as well as overflows, font issues, cultural issues (wrong currency used or promoting alcohol in a game for the German market) and functional issues (buttons that don’t work).
MTPE
MTPE stands for Machine Translation Post-Editing. If you want to know more about machine translation and where it succeeds or fails, you can find that in my article Machine Translation: How accurate is Google Translate? – but for now let’s just say it generally needs post-editing to produce useful results.
With MTPE, the idea is to have a machine do the heavy lifting, then pay a proofreader to fix the machine-translated text. I believe MTPE has its place in certain areas, such as technical text with simply structured sentences that follow a regular pattern. In video game translation as well as literary or marketing translation, I can only strongly discourage the use of machine translations. The results will likely not be very good, and by using MTPE, editors will be unnecessarily fixated on the initial text that is shown to them.
Lockit
Lockit or LocKit is short for localization kit and is a bundle of files provided to the translator so they can proceed with localization. This can include any number of things, the most important being the source file or files that need translating. Ideally, the lockit will also include various reference files, such as a glossary or termbase, a translation memory, a style guide, character sheet (with info on the background or personalities of the characters in the game), previous translations (if the game is part 2 of a series) or maybe even a playable build of the game.
What a client puts in a lockit is up to them, of course, and if the game is the first of its kind, there might not be any glossaries or style guides to share. It’s still important to consider that translators need as much context as possible, as it can be very hard to guess what text is referring to without an image to go with it. The most pleasant translations of games I have done came with a mostly functional English build that I could follow along with while translating.
I hope this little glossary of localization terms has been helpful to you. If there are any other terms or concepts that puzzle you, be sure to let me known in a comment or e-mail. If you’re interested in my video game translation services, don’t hesitate to contact me.
Finally, subscribe to my newsletter to never miss another one of my posts.




I would like to receive your newsletter
Regards
JULIETA
Done. 🙂